Two years ago I replaced my Airpods with the Airpods Pro.
The upgrade was significant and necessary, as after 2-3 years, the battery of the old ones was worn out.
Some months ago (as the Airpods where nearing their 2 year anniversary), the first major issues started to come up. The right microphone wouldn’t work well, when touching the right Airpod I would hear a cracking noise, and the battery was slowly decaying.
Turns out that there’s a service program from Apple and Airpods exhibiting crackling or static sounds are eligible.
So I went into the Apple Store in Amsterdam and got a new pair!
Some notes:
You need a genius appointment if you want help quickly
They told me the test process would take two hours, so I got back to the office. Once I got back (15’ later) they called me. They were ready
Even though only one Airpod would malfunction, in their test, both were faulty. I don’t know if this is true, or if they simply didn’t want to give a customer one with a new battery and one with a 2 years old battery
The actual price for 2 new Airpods is EUR 180.16. Phew!
Now my case has an old battery. I’d love to buy the new Airpods Pro 2 case, but there is inconclusive evidence on a reddit thread about the compatibility.
OpenAI has just open sourced Whisper, an automatic speech recognition.
I just tried it out and I’m blown away.
Installation was a piece of cake (even though there was a missing step, but I’ve opened a pull request to help out), and once you’re there, it literally takes seconds to start transcribing:
whisper my_file.m4a --model base
The output is ready to be used in subtitles programs as well, as it looks like this
[01:23.000 --> 01:31.000] Camilla, first question, what keeps you awake at night?
[01:31.000 --> 01:36.000] Around data analytics, let's keep it to that box
[01:36.000 --> 01:45.000] Yeah, so I think we have three different, very specific business units
[01:45.000 --> 01:52.000] And we have teams that are divided between being masters in data in analytics
[01:52.000 --> 01:57.000] And they know much more than I do to having people who are just hearing about data
[01:57.000 --> 02:00.000] And it's a very, very scary topic
[02:00.000 --> 02:08.000] And what I'm supposed to be doing is raising the level so that we at least come to the same level of understanding
[02:08.000 --> 02:13.000] What does it mean for me? What does it mean for the company? What is data?
[02:13.000 --> 02:17.000] I mean we really go into those type of basic conversations
[02:17.000 --> 02:23.000] So that really is a challenge and an opportunity, huge opportunity
[02:23.000 --> 02:26.000] So that keeps me awake at night, how do I do that?
(The audio was taken from an interview I had with Camilla Björkqvist last year).
Caddy is an open source web server that can be used to, among others, proxy other sorts of server adding https with valid certificates.
At home, I have a Unifi controller that uses https but has no valid certificate, so I decided to expose it through caddy.
Since I run caddy as an unpriviliged user, it listens to port 2016 for http and 2017 for https. My router then listens to port 80 / 443 and reroutes to port 2016 / 2017 on the host running caddy.
The working configuration I came up with my Caddyfile is pretty simple
{
http_port2016https_port2017unifi.lanzani.nl {
reverse_proxy 127.0.0.1:8443 { # the unifi controller runs on the same machine as caddy
transporthttp {
tls_insecure_skip_verify # we don't verify the controller https cert
}
header_up-Authorization # sets header to be passed to the controller
}
}
}
Have you ever thought why the flight attendants bother giving safety instructions? Do you listen to them?
Flight attendants are stuck. They can’t go off script.
Probably a long time ago, there were tests on how to deliver those safety instructions to passengers.
The current way was tested not with busy passengers needing to get somewhere, but people recruited for the purpose. It probably fared better than anything else.
Yet, when applied in real life, it sucks. We don’t listen to what they say.
I see the same mistake made in data science: people test their model with real data, but not in production.
I used to tell my classes a story of a big online retailer developing a much better version of their recommender — “customers who bought this, also bought that” type of thing.
With the new recommender, fewer clicks were necessary to understand the set of items the customer wanted to buy.
Before rolling out, they A/B tested it — luckily.
To their surprise, people exposed to the new version, were closing their browser more quickly without buying!
Some of them were logged in, so they decided to investigate.
It turns out, customers were creeped out by the eerie accuracy of the new recommender. They left the website, afraid of what else the retailer would find out about them.
The retailer went back to the old version.
It doesn’t matter how enthusiast data scientists are about the model.
Without testing in production, it counts for nothing.
Algorithms can have serious consequences on the lives of people around you.
The Dutch tax office used the second nationality as a feature in their model — to find possible fraudulent behavior in their allowances scheme.
There were two problems with their approach:
First of all, it was unlawful in the Netherlands. This was the biggest issue, algorithm, or no algorithm
The second one was that the algorithm didn’t say why it flagged an individual.
Is this problematic?
Yes, it is! If you don’t know why someone is flagged, then you will be looking into everything trying to find something is wrong. And sometimes that something is a technicality such as forgetting to sign a form — a far cry from committing fraud!
So how do you do it right?
A couple of years ago, I was called by a bank that had a high-performing machine learning model (an isolation forest) to flag correspondent banking transactions that were suspicious.
The problem is that isolation forests are not very explainable, you don’t know why they flag something.
However, the bank found it unacceptable for the model to just report a transaction to an analyst.
The analyst would have engaged in the same behavior the Dutch office engaged in: find anything that was not 100% kosher. Of course, if you’re not 100% within the lines, it doesn’t mean you’re committing fraud. It can be as silly as forgetting to sign a form.
What I did back then was to develop a geometric model that would explain why the isolation forest model was flagging transactions.
Please do the same with models that can have nefarious effects. I don’t care if you’re wrong about my taste in fashion when I browse Amazon.
I very much care if my life gets destroyed though!
Then, activate Launchbar (⌘ Space on my Mac), and then launch its index (⌥ ⌘ I).
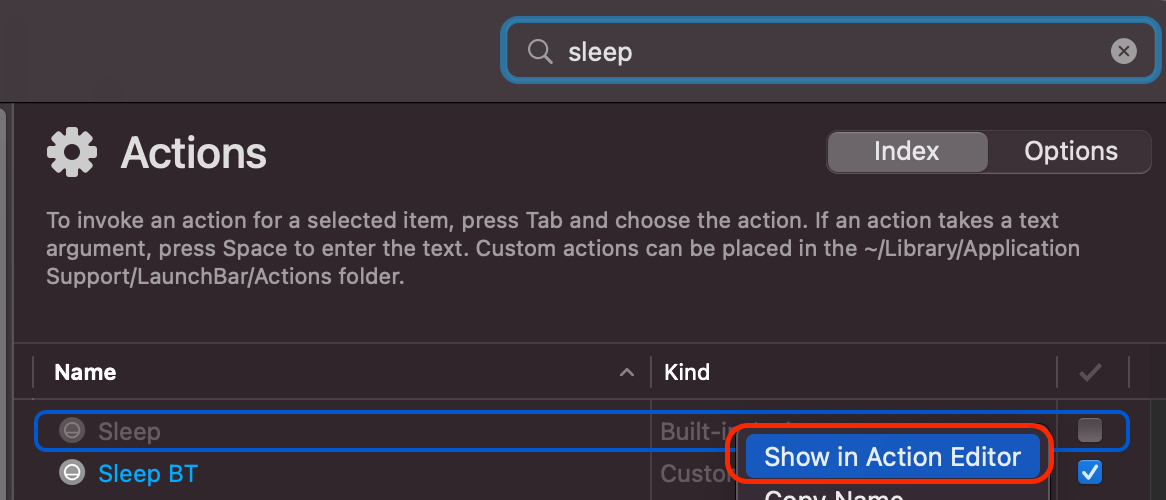
In the general section on the left, click on Action. From there, use the search bar to find the
Sleep action, disable its checkbox, right-click, and select Show in Action Editor.
Then right-click the Sleep action and duplicate it.
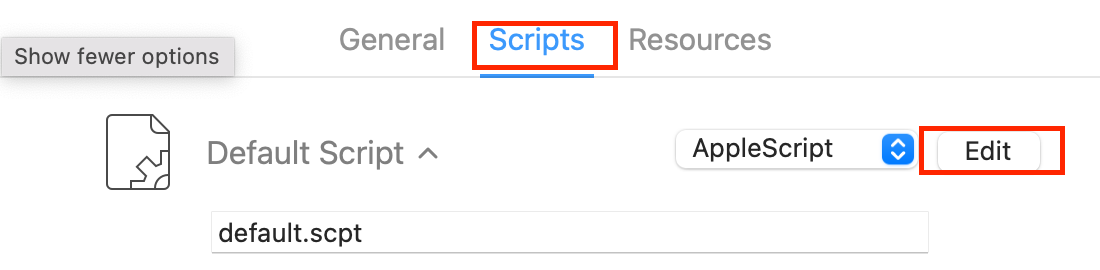
Once you have duplicated, rename it to Sleep BT (or whatever), click on Scripts, and click on
Edit.
You might read of yet another unicorn raising money.
But I read about a company that deeply cared about its (Mac) users and that now sees the future in B2B services.
I don’t fault them.
1Password has been profitable from the start — contrary to many others. It did so by building a delightful product (I have been a user since Christmas 2008).
But even though they had a lucrative life-style business, there is way more money in the B2B market. So they took that route and are not looking back.
A single company — where you could easily have 1000 employees — earns them 8$ per employee a month (8000$/month). That’s equal to 1600 1Password family plans. A feature winning them a family is worth nothing. A feature winning them a company? Easily $100k per year!
And that future is already here.
1Password 8 is subscription only, while v7 had a fixed-price version. Why? This is how enterprise buys software nowadays.
1Password 7 was a native Mac app. 1Password 8 is an Electron app. They can pull it off as business users already have all sorts of crap on their machine. Electron is one of the good ones there.
In the future, more might come and I wish this wasn’t the case. 1Password is the app I couldn’t live without.
If you work with Python on macOS and are trying to let your kids play with things like turtle
you will encounter errors such as
>>>import turtle
Traceback (most recent call last):
File "<stdin>", line 1, in<module> File "~/.pyenv/versions/3.7.4/lib/python3.7/turtle.py", line 107, in<module>import tkinter as TK
File "~/.pyenv/versions/3.7.4/lib/python3.7/tkinter/__init__.py", line 36, in<module>import _tkinter # If this fails your Python may not be configured for TkModuleNotFoundError: No module named '_tkinter'
If you use pyenv and brew there’s a simple way to fix it:
brew install tcl-tk
brew install pyenv # skip if you already have pyenv installedexport PATH="/usr/local/opt/tcl-tk/bin:$PATH"export LDFLAGS="-L/usr/local/opt/tcl-tk/lib"export CPPFLAGS="-I/usr/local/opt/tcl-tk/include"export PKG_CONFIG_PATH="/usr/local/opt/tcl-tk/lib/pkgconfig"export PYTHON_CONFIGURE_OPTS="--with-tcltk-includes='-I$(brew --prefix tcl-tk)/include' \
--with-tcltk-libs='-L$(brew --prefix tcl-tk)/lib -ltcl8.6 -ltk8.6'"pyenv uninstall 3.8.2 # substitute here the version you're using or skip if you were not using pyenvpyenv install $(pyenv install --list | grep -v - | grep -v b | tail -1)